Rangka Pantas
Catatan ini mengandungi bahagian berikut:
- Cara Menggunakan Ejen API Async dalam LangChain
- Kaedah 1: Menggunakan Pelaksanaan Bersiri
- Kaedah 2: Menggunakan Perlaksanaan Serentak
- Kesimpulan
Bagaimana untuk Menggunakan Ejen API Async dalam LangChain?
Model sembang melaksanakan berbilang tugas secara serentak seperti memahami struktur gesaan, kerumitannya, mengekstrak maklumat dan banyak lagi. Menggunakan ejen API Async dalam LangChain membolehkan pengguna membina model sembang yang cekap yang boleh menjawab berbilang soalan pada satu masa. Untuk mengetahui proses menggunakan ejen API Async dalam LangChain, cuma ikut panduan ini:
Langkah 1: Memasang Rangka Kerja
Pertama sekali, pasang rangka kerja LangChain untuk mendapatkan kebergantungannya daripada pengurus pakej Python:
pip pasang langchain
Selepas itu, pasang modul OpenAI untuk membina model bahasa seperti llm dan tetapkan persekitarannya:
pip pasang openai
Langkah 2: Persekitaran OpenAI
Langkah seterusnya selepas pemasangan modul ialah menetapkan persekitaran menggunakan kunci API OpenAI dan API Serper untuk mencari data daripada Google:
import awak
import getpass
awak . lebih kurang [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
awak . lebih kurang [ 'SERPER_API_KEY' ] = getpass . getpass ( 'Kunci API Serper:' )
Langkah 3: Mengimport Perpustakaan
Sekarang setelah persekitaran ditetapkan, hanya import perpustakaan yang diperlukan seperti asyncio dan perpustakaan lain menggunakan kebergantungan LangChain:
daripada langchain. ejen import initialize_agent , load_toolsimport masa
import asyncio
daripada langchain. ejen import Jenis Agen
daripada langchain. llms import OpenAI
daripada langchain. panggilan balik . stdout import StdOutCallbackHandler
daripada langchain. panggilan balik . pengesan import LangChainTracer
daripada aiohttp import ClientSession
Langkah 4: Sediakan Soalan
Tetapkan set data soalan yang mengandungi berbilang pertanyaan yang berkaitan dengan domain atau topik berbeza yang boleh dicari di Internet (Google):
soalan = ['Siapakah pemenang kejohanan Terbuka A.S. pada 2021' ,
'Berapa umur teman lelaki Olivia Wilde' ,
'Siapakah pemenang gelaran dunia formula 1' ,
'Siapa yang memenangi perlawanan akhir wanita Terbuka AS pada 2021' ,
'Siapa suami Beyonce dan Berapakah umurnya' ,
]
Kaedah 1: Menggunakan Pelaksanaan Bersiri
Setelah semua langkah selesai, hanya laksanakan soalan untuk mendapatkan semua jawapan menggunakan pelaksanaan bersiri. Ini bermakna bahawa satu soalan akan dilaksanakan/dipaparkan pada satu masa dan juga mengembalikan masa lengkap yang diperlukan untuk melaksanakan soalan ini:
llm = OpenAI ( suhu = 0 )alatan = load_tools ( [ 'google-header' , 'llm-math' ] , llm = llm )
ejen = initialize_agent (
alatan , llm , ejen = Jenis Agen. ZERO_SHOT_REACT_DESCRIPTION , bertele-tele = betul
)
s = masa . perf_counter ( )
#mengkonfigurasi pembilang masa untuk mendapatkan masa yang digunakan untuk proses lengkap
untuk q dalam soalan:
ejen. lari ( q )
berlalu = masa . perf_counter ( ) - s
#cetak jumlah masa yang digunakan oleh ejen untuk mendapatkan jawapan
cetak ( f 'Siri dilaksanakan dalam {elapsed:0.2f} saat.' )
Pengeluaran
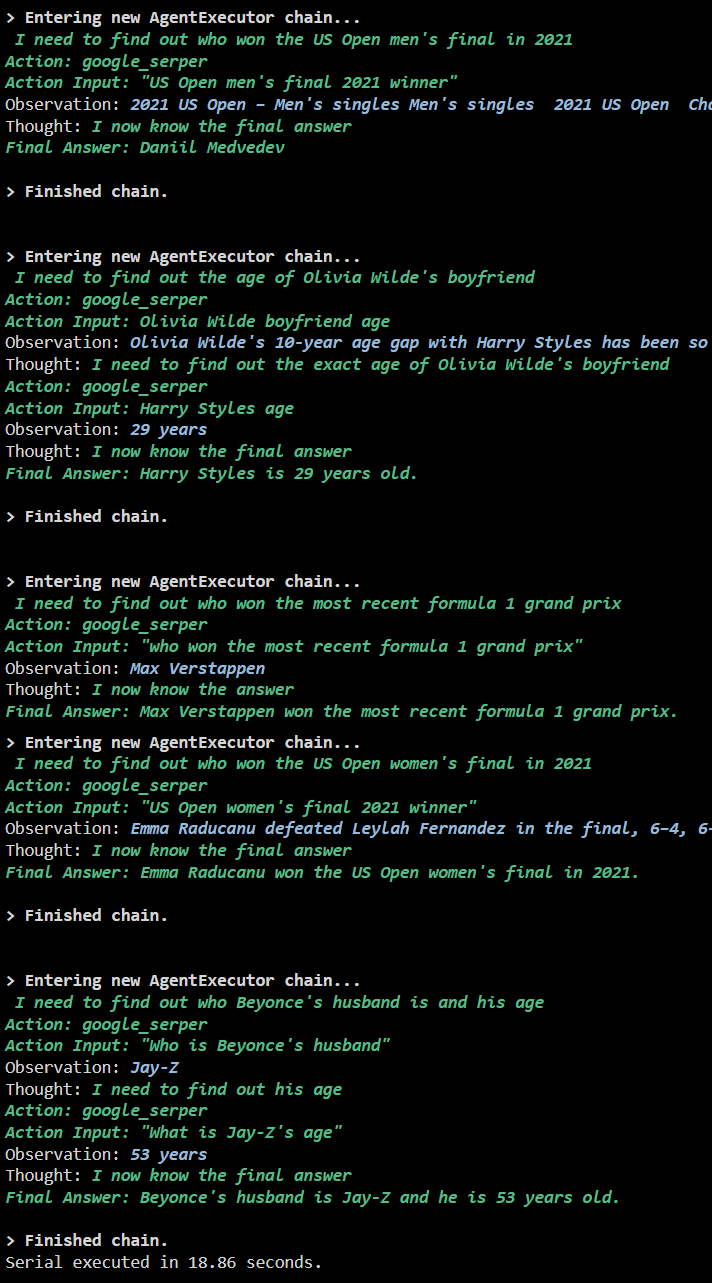
Tangkapan skrin berikut memaparkan bahawa setiap soalan dijawab dalam rantaian berasingan dan sebaik sahaja rantaian pertama selesai maka rantai kedua menjadi aktif. Pelaksanaan bersiri mengambil lebih banyak masa untuk mendapatkan semua jawapan secara individu:
Kaedah 2: Menggunakan Perlaksanaan Serentak
Kaedah pelaksanaan Serentak mengambil semua soalan dan mendapat jawapannya serentak.
llm = OpenAI ( suhu = 0 )alatan = load_tools ( [ 'google-header' , 'llm-math' ] , llm = llm )
#Mengkonfigurasi ejen menggunakan alat di atas untuk mendapatkan jawapan secara serentak
ejen = initialize_agent (
alatan , llm , ejen = Jenis Agen. ZERO_SHOT_REACT_DESCRIPTION , bertele-tele = betul
)
#configuring pembilang masa untuk mendapatkan masa yang digunakan untuk proses yang lengkap
s = masa . perf_counter ( )
tugasan = [ ejen. penyakit ( q ) untuk q dalam soalan ]
tunggu asyncio. berkumpul ( *tugas )
berlalu = masa . perf_counter ( ) - s
#cetak jumlah masa yang digunakan oleh ejen untuk mendapatkan jawapan
cetak ( f 'Serentak dilaksanakan dalam {elapsed:0.2f} saat' )
Pengeluaran
Pelaksanaan serentak mengekstrak semua data pada masa yang sama dan mengambil masa yang lebih singkat daripada pelaksanaan bersiri:
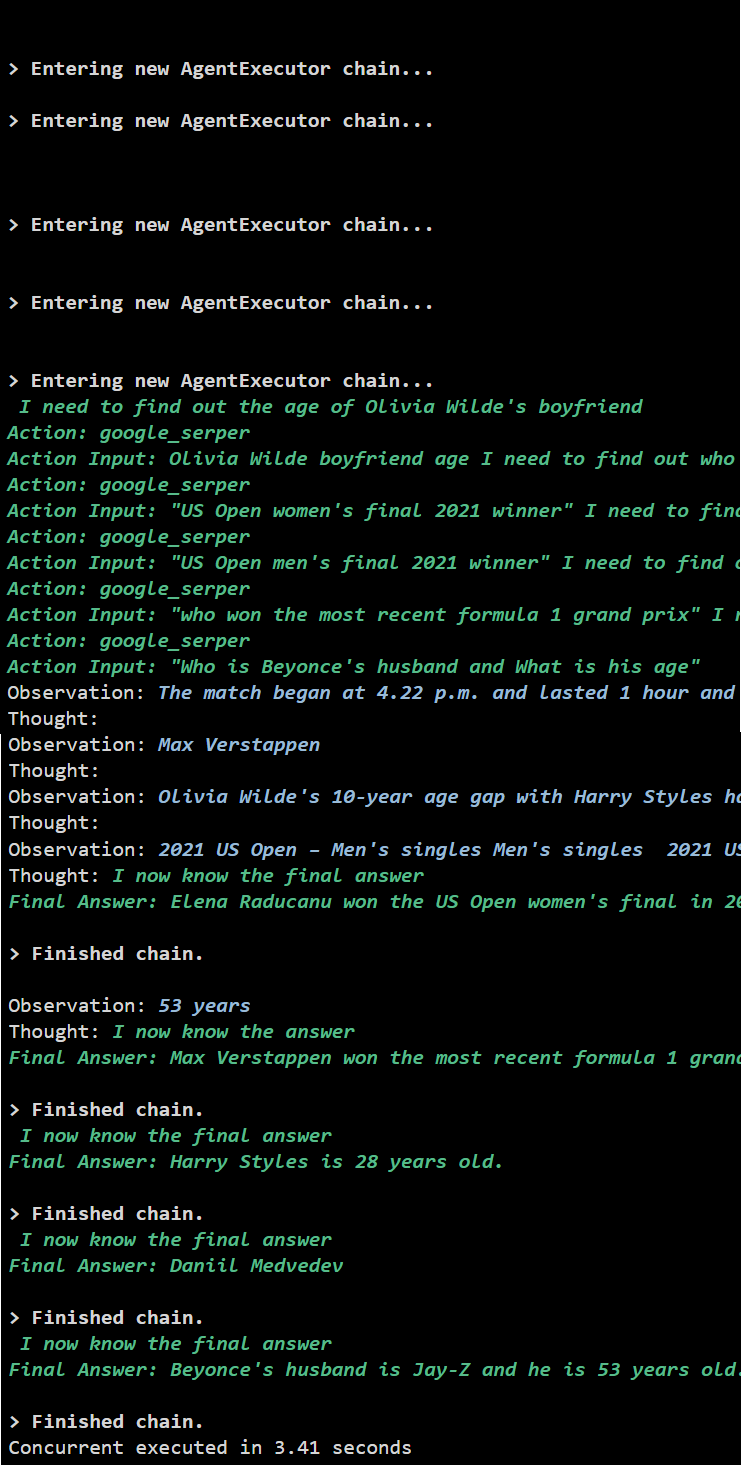
Itu sahaja tentang menggunakan ejen API Async dalam LangChain.
Kesimpulan
Untuk menggunakan ejen API Async dalam LangChain, cuma pasang modul untuk mengimport perpustakaan daripada kebergantungan mereka untuk mendapatkan perpustakaan asyncio. Selepas itu, sediakan persekitaran menggunakan kunci OpenAI dan Serper API dengan melog masuk ke akaun masing-masing. Konfigurasikan set soalan yang berkaitan dengan topik yang berbeza dan laksanakan rantaian secara bersiri dan serentak untuk mendapatkan masa pelaksanaannya. Panduan ini telah menghuraikan proses penggunaan ejen API Async dalam LangChain.