'Panda' ialah alat berprestasi tinggi untuk persekitaran ular sawa. Ia adalah kod sumber 'terbuka' untuk analisis data. Gabungan panda dan kaedah cantum panda digunakan untuk penyatuan dua bingkai data bersama-sama menjadi satu bingkai data. Dalam kedua-dua kaedah panda, perbezaannya ialah fungsi 'bergabung' panda bergabung dengan bingkai data menggunakan indeks. Manakala fungsi 'gabung' panda bergabung dengan kerangka data dengan menggunakan indeks dan kaedah lajur di mana kita boleh memilih lajur yang dikehendaki sendiri. Kaedah gabungan panda digunakan kebanyakannya berbanding kaedah gabungan panda. Perisian yang akan kami gunakan untuk pelaksanaan ialah perisian 'spyder', yang berada dalam persekitaran ular sawa yang akan memberi kami faedah untuk pelaksanaan kod kaedah gabungan panda() dan fungsi kaedah gabungan panda().
Sintaks Kaedah Pandas Join().
“df1. sertai ( df2 ) ”'df' dalam sintaks di atas ialah singkatan daripada 'bingkai data'. Terdapat dua bingkai data dalam sintaks dengan fungsi 'gabungan titik', iaitu untuk memanggil kaedah. Ia adalah kaedah panda untuk menyertai dua bingkai data. Ia berfungsi dengan menggunakan indeks untuk menggabungkan bingkai data dalam satu.
Sintaks Kaedah Pandas Merge().
“df1. bercantum ( df2 , pada = 'nama_lajur' ) ”Sintaks kaedah gabungan panda mempunyai dua bingkai data sebagai 'df1' dan 'df2'. Fungsi 'gabungan titik' memanggil kaedah untuk menggabungkan kedua-dua bingkai data dengan penampilan lajur terbalik.
Kami akan merangkumi cara berikut untuk menggabungkan dua bingkai data untuk menggunakan kaedah gabungan panda dan gabungan panda:
- Kaedah Pandas Join bertindih.
- Panda menyertai kaedah menggunakan tetapan semula indeks.
- Kaedah gabungan panda (lajur 'kiri dan kanan').
- Kaedah gabungan panda secara eksplisit.
Mencipta Bingkai Data untuk Pelaksanaan Kaedah Gabungan Panda dan Pandas
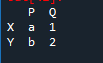
Pertama, kita perlu membuat bingkai data. Untuk itu, kami akan menggunakan alat 'spyder'. Selepas membukanya, mula menulis kod. Import panda sebagai 'pd' untuk persatuan perpustakaan panda. Kami mempunyai pembolehubah kerangka data sebagai 'x', 'y', 'p', dan 'q yang sepadan dan 'a' dengan nilai '1' dan 'b' dengan nilai yang ditetapkan sebagai '2'.

Output ialah 'df' yang dibuat dengan nilai yang diberikan. Kita boleh menjadikannya sebesar data.
Mencipta Bingkai Data Lain
Kita kena buat satu lagi dataframe, untuk memahami kaedah cantuman panda dan cantuman panda dengan jelas. Di sini, kami telah 'df' mencipta sama seperti 'df' di atas, hanya nilai pembolehubah yang diberikan adalah berbeza. Kami mempunyai 'h', 'j', 's' dan 'd', manakala tetapkan nilai 'b' dengan nilai '8' dan 'Y' dengan nilai '3'.

Output menunjukkan 'df' mudah yang dibuat.

Contoh # 01: Kaedah Sertai Panda (bertindih)
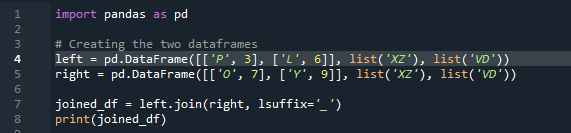
Sekarang, kita akan melihat bagaimana untuk menyertai dua bingkai data dengan kaedah gabungan panda. Untuk kaedah ini, kami boleh memilih lajur pilihan anda yang ingin kami usahakan daripada bingkai data. Kami telah mengambil contoh dengan lajur bertindih 'kiri' daripada 'df', jadi kami boleh membetulkannya dengan 'akhiran' untuk mengatasi pertindihan data. Di sini, pembolehubah yang digunakan ialah “x”, “z”, “v”, “d”. “p”, “o”, “l”, dan “y” dengan nilai yang ditetapkan sebagai “3”, “6”, “7”, dan “9”. '.join' memanggil kaedah, dengan penjajaran ditetapkan ke gabungan kiri dengan akhiran 'df' kanan. ”. 'Akhiran' yang digunakan dalam kod adalah kerana dalam bingkai data, terdapat dua lajur yang mempunyai nama yang sama iaitu 'kunci' dan yang tidak akan bertindih dengan data.
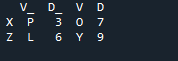
Output tidak memaparkan data bertindih dengan kaedah menyertai dua 'df' menggunakan kaedah gabungan panda.
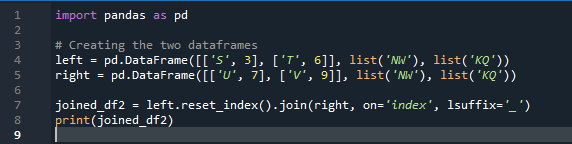
Contoh # 02: Kaedah Sertai Panda Menggunakan Tetapan Semula Indeks
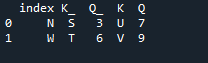
Dalam contoh ini, kami secara berasingan akan menentukan lajur dengan parameter 'hidup' untuk digunakan sebagai 'kunci' dalam gabungan kaedah yang membantu dalam menyertai dua bingkai data. perkara gabungan dilakukan dengan parameter ini. Selain itu, indeks salah satu daripada dua 'df' hendaklah serupa untuk menyertainya. Jenis data atau data yang serupa yang digunakan untuk tujuan yang sama boleh digabungkan untuk diproses. Ini akan menggunakan indeks masih, menggunakan dari kanan. Pembolehubah tersebut ialah “s”, “t”, “u”, “v”, “n”, ‘w”, “k”, dan “q”. Nilai yang diberikan ialah “3”, “6”, “7” dan “9”. 'Indeks titik semula' ialah kaedah panda untuk menetapkan semula indeks 'df'. Indeks tetapan semula menetapkan semua integer penyenaraian bingkai data anda daripada 0 sehingga data bingkai data dipanjangkan.
Berikut ialah output yang dipaparkan dengan kaedah gabungan indeks 'kunci' panda.
Contoh # 03: Kaedah Gabungan Panda (lajur 'kiri dan kanan')
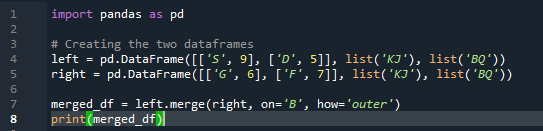
Kaedah gabungan melakukan operasi yang sama seperti kaedah gabungan panda. Kedua-dua kaedah adalah untuk menggabungkan data pada kerangka data yang serupa. Kaedah gabungan adalah lebih serba boleh yang memerlukan menentukan kunci. Kami juga boleh menentukannya pada lajur kiri dan kanan bergantung pada kerja bingkai data anda. Pembolehubah dalam kod tersebut ialah “s”, “d”, “g”, “f”, “k”, “j”, “b” dan “q”. nilai yang diberikan ialah “9”, “5”, “6” dan “7”. Pelaksanaan 'bergabung' luar dilakukan pada kedua-dua 'df' dengan menggunakan parameter 'bagaimana' fungsi kaedah cantum panda.
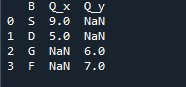
Output yang kita lihat menunjukkan data gabungan kedua-dua bingkai data. 'NaN' mewakili 'bukan nombor' yang bermaksud bahawa jika tiada nombor yang ditetapkan dalam data, 'NaN' ditunjukkan di sana.
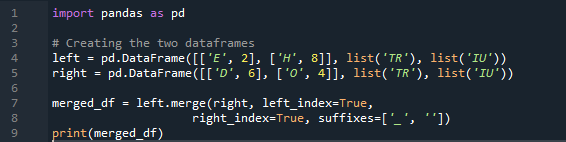
Contoh # 04: Kaedah Gabungan Secara Eksplisit
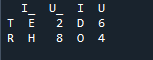
Di sini, dalam contoh ini, kaedah gabungan ialah pemusnahan indeks dan nilai indeks tidak diandaikan pada bingkai data. Kami akan melakukan kaedah ini mengikut kerja yang perlu dilakukan, di mana yang dinyatakan secara eksplisit adalah untuk membuat susulan. Ia akan menggabungkan data berdasarkan indeks kiri atau indeks kanan dengan parameter. Pembolehubah dalam rangka data ini ialah “t”, “r”, “I”, “u”, “h”, “o”, “e”, dan “e”. Nilai yang diberikan ialah '2', '4', '6' dan '4'. Contoh kaedah cantum panda di atas dengan pemilihan lajur mengikut keperluan adalah kaedah yang paling sesuai dan bernilai untuk menyertai dua kerangka data. Menyemak pada penghujung baris kod tentang kunci gabungan yang unik dalam set data.
Dalam output di bawah indeks tidak ditunjukkan tanpa indeks tetapi fungsi dilakukan berdasarkan indeks kanan dan kiri.
Kesimpulan
Kaedah merge() dan join() adalah kedua-dua kaedah yang sangat mudah dan berkesan. Kedua-dua fungsi ini digunakan untuk menyertai dua kerangka data berasingan pada bingkai data yang sama tetapi mempunyai penggunaan yang berbeza bergantung pada kes. Dalam artikel ini, kami telah mempelajari perbezaan utama antara kaedah gabungan dan gabungan panda. Selepas melakukan contoh dan memahami kaedah gabungan panda, kami akan menyimpulkannya dengan pengetahuan bahawa, jika kami mahukan penyambungan gaya pangkalan data yang lebih fleksibel dan, adalah lebih baik untuk menggunakan kaedah gabungan panda. Sebaliknya, jika kita ingin melakukan gabungan rangka data dengan indeks secara meluas, kita boleh menggunakan fungsi kaedah pandas join().