'Dalam 'panda', kita boleh membaca fail teks dengan mudah dengan bantuan kaedah 'panda'. 'Panda' memberi kita peluang untuk membaca fail teks. 'Panda' memberikan kaedah terbina dalam yang berbeza untuk membaca fail teks. Kami akan membincangkan semua kaedah dalam tutorial ini bersama-sama dengan semua parameter di sini dan akan menerangkannya secara terperinci. Selain itu, kami akan membaca fail teks dalam 'pandas' dengan menggunakan kaedah 'pandas' dalam kod kami di sini.'
Kaedah untuk Membaca Fail Teks dalam 'pandas'
Dalam 'pandas,' kami mempunyai tiga kaedah yang membantu kami membaca fail teks. Kami juga telah melakukan beberapa contoh di sini di mana kami membaca fail teks. Kaedah yang disediakan oleh 'pandas' dibincangkan di bawah:
-
- Dengan menggunakan kaedah pd.read_csv().
- Dengan menggunakan kaedah pd.read_table().
- Dengan menggunakan kaedah pd.read_fwf().
Sekarang, kami menerangkan sintaks semua kaedah ini dan juga membincangkan parameter semua kaedah secara terperinci dalam tutorial ini.
Sintaks read_csv()
pd.read_csv ( 'filename.txt', sep =' ', kepala =Tiada, nama = [ “Col_name1”, “Col_name2, “Col_name2”, ………….. ] )
Dalam kaedah ini, kami mula-mula menambah nama fail teks yang datanya ingin kami baca, dan ia adalah parameter pertama kaedah ini. Kemudian, kami meletakkan 'sep,' yang merupakan pemisah dalam kaedah ini, dan kami meletakkan ruang di sini sebagai watak supaya ia akan menganggap ruang sebagai pemisah. Selepas ini, kami mempunyai parameter pengepala, dan nilai 'Tiada' parameter ini digunakan, jadi ia akan mencipta pengepala lalai, dan jika kami tidak menambah parameter ini, maka ia akan mempertimbangkan baris pertama fail teks sebagai tajuk. Dalam parameter 'nama', kita boleh menambah nama lajur yang perlu kita tambah sebagai pengepala.
Sintaks read_table()
pd.read_table ( 'filename.txt' , pembatas = '' )
Dalam kaedah ini, kami meletakkan nama fail fail teks sebagai parameter pertama. Dalam pembatas, apabila kita meletakkan ' ', maka ia akan mengambil watak ruang sebagai pemisah.
Sintaks read_fwf()
pd.read_fwf ( 'filename.txt' )
Kaedah ini hanya mengambil satu parameter, iaitu nama fail teks.
Sekarang, kami akan menggunakan kaedah ini untuk membaca fail teks dalam kod 'pandas' dan menunjukkan data fail teks pada terminal.
Contoh # 01
Aplikasi 'Spyder' ada di sini di mana kami telah melakukan semua kod ini yang dibentangkan dalam tutorial ini. Fail teks yang datanya ingin kami baca ditunjukkan di bawah. Kami akan menggunakan kaedah 'read_csv()' untuk membaca fail teks ini dalam 'pandas'.
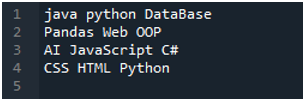
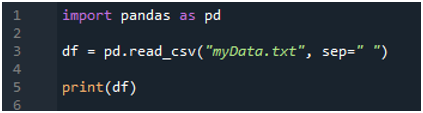
Kami mula-mula mengimport perpustakaan 'pandas' kerana kami ingin menggunakan kaedah 'read_csv()', dan ia adalah kaedah 'pandas'. Kami hanya mengakses kaedah ini apabila kami telah mengimport perpustakaan 'pandas'. Di sini, kami menyebut 'pandas sebagai pd', jadi 'pd' ini diletakkan dengan nama kaedah untuk menggunakannya. Selepas ini, kami mencipta pembolehubah 'df' di sini, yang digunakan untuk menyimpan data fail teks selepas membaca. Kami meletakkan kaedah 'pd.read_csv()' di sini, yang membantu dalam membaca fail teks dan menukar data fail teks ke dalam DataFrame dan menyimpannya dalam pembolehubah 'df'.
Kami telah menghantar nama fail, iaitu 'myData.txt,' di sini, dan kemudian kami menggunakan 'sep' dan menetapkan aksara kosong kepada 'sep' ini. Jadi, aksara kosong ini berfungsi sebagai pemisah dalam fail teks. Kemudian, kami menggunakan 'print()' di bawah, yang digunakan untuk mencetak data fail teks. Ia akan memaparkan data fail teks dalam bentuk DataFrame.
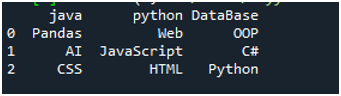
Untuk pelaksanaan kod ini, kita perlu menekan 'Shift+Enter,' dan output akan dipaparkan pada terminal 'Spyder's'. Hasil kod di atas dipaparkan dalam tangkapan skrin yang diberikan, dan anda boleh melihat bahawa data fail teks dipaparkan sebagai DataFrame, dan baris pertama fail teks kami dibentangkan di sini sebagai nama lajur DataFrame tersebut. Ia juga memisahkan data di mana watak ruang hadir dalam fail teks.
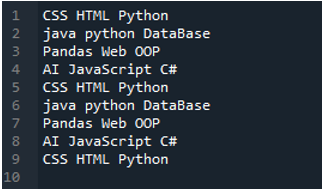
Contoh # 02
Fail teks yang akan kami baca dalam contoh ini ditunjukkan di sini, dan kami sekali lagi akan menggunakan kaedah 'read_csv()' tetapi dengan parameter yang berbeza.
Kaedah 'pandas' 'pd.read_csv()' digunakan dan kami menghantar tiga parameter di sini. Pertama, kami meletakkan nama fail, iaitu 'Record.txt'. Parameter kedua ialah parameter 'sep' dan memberikan aksara kosong kepadanya, dan kemudian kita mempunyai parameter ketiga di mana kita menetapkan 'pengepala' dan melaraskannya kepada 'Tiada', jadi ia akan mencipta pengepala lalai DataFrame apabila kita melaksanakan kod ini. Kami telah menyimpan semua ini dalam pembolehubah 'My_Record' dan juga menambah 'My_Record' dalam fungsi 'print()' untuk mencetak.

Semua data disimpan dalam DataFrame, dan ia memisahkan data di mana watak ruang hadir dalam data fail teks. Selain itu, ia mencipta pengepala lalai DataFrame di sini kerana kami melaraskan parameter 'pengepala' kepada 'Tiada'.
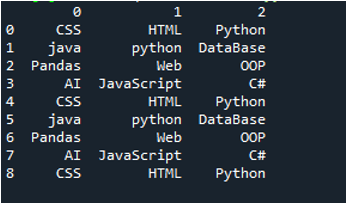
Contoh # 03
Fail teks contoh ini dipaparkan dan kami akan menggunakan kaedah 'read_csv()' sekali lagi dengan parameter yang diubah suai.
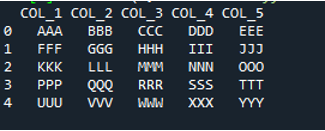
Dalam kod ini, empat parameter dihantar di sini kepada kaedah 'pandas' 'pd.read_csv()'. Nama fail teks ialah parameter pertama. Parameter 'sep' diberikan aksara kosong dalam parameter kedua. Parameter 'header' ditetapkan kepada 'Tiada' dalam argumen ketiga, dan sebagai parameter keempat, kami telah menetapkan 'nama' yang akan muncul sebagai nama lajur DataFrame selepas membaca fail teks, dan nama lajur ini ialah “COL_1, COL_2, COL_3, COL_4 dan COL_5”. Semua maklumat ini telah disimpan dalam pembolehubah 'My_Record' dan 'My_Record' juga telah ditambahkan pada kaedah 'print()' supaya ia akan mencetak pada terminal.

Semua maklumat fail teks dipaparkan di sini sebagai DataFrame, dan ia juga memisahkan data di mana ruang ditambah dalam fail teks. Ia juga menambah nama lajur dengan sewajarnya, yang telah kami tambahkan di atas dalam kod.
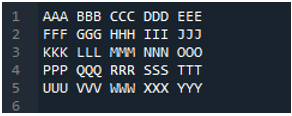
Contoh # 04
Ini ialah fail teks yang akan kita baca dalam contoh ini dengan menggunakan kaedah lain, kaedah 'pd.read_table()'.
Kaedah 'pd.read_table()' ditambahkan di sini untuk membaca fail teks dan kami menambah 'ABC.txt,' iaitu nama fail teks. Kaedah ini membantu dalam membaca fail teks, dan juga, kami telah melaraskan parameter 'pembatas' kepada aksara ruang, jadi ia juga akan berfungsi seperti pemisah yang telah kami jelaskan di atas. Kemudian semua data fail teks disimpan dalam pembolehubah 'My_Data' dan juga dicetak di sini.

Baris awal fail teks kami ditunjukkan di sini sebagai nama lajur DataFrame dan data fail teks dicetak sebagai DataFrame. Selain itu, ia memisahkan data fail teks di mana watak ruang terdapat di dalamnya.
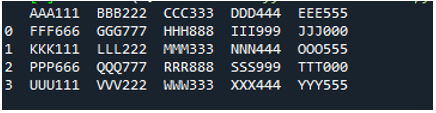
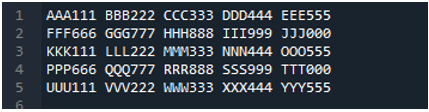
Contoh # 05
Sekarang, fail teks mengandungi data, yang dipaparkan di bawah. Kami akan menggunakan 'read_fwf()' kali ini dan akan menunjukkan cara ia memaparkan data selepas membaca fail teks.
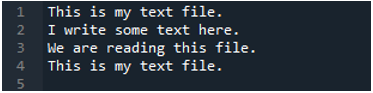
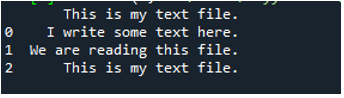
Seperti yang kita tahu bahawa kaedah 'read_fwf()' ini hanya mengambil satu parameter, iaitu nama fail yang ingin kita baca. Kami menambah 'textfile.txt' di sini, iaitu nama fail teks kami dan menetapkan kaedah panda ini kepada pembolehubah 'File_Data', yang akan menyimpan data fail teks ini. Kemudian kami meletakkan 'print(File_Data)' supaya ia juga mencetak data ini.

Di sini, semua data fail teks ditunjukkan. Ia tidak memisahkan data yang terdapat aksara ruang kerana tiada parameter seperti 'Sep' atau 'pembatas' dalam fungsi ini.
Kesimpulan
Tutorial ini menerangkan cara membaca fail teks dalam 'pandas' dan kaedah yang digunakan untuk membaca fail teks dalam 'pandas'. Kami telah membincangkan semua kaedah yang membantu kami membaca fail teks dalam 'pandas'. Kami telah meneroka tiga kaedah 'pandas' yang berbeza untuk membaca fail teks kami dalam 'pandas' dalam tutorial ini. Kami juga telah menerangkan sintaks semua kaedah serta parameter semua kaedah secara terperinci di sini dan telah membaca banyak fail teks dengan menggunakan kaedah berbeza dengan semua parameter yang mungkin dalam tutorial ini.