“Nilai Dipisahkan Koma (CSV) ialah salah satu format data yang paling serba boleh dan mudah digunakan. Ia adalah format data ringan yang membolehkan pembangun dan aplikasi memindahkan dan menghuraikan data dari satu sumber ke sumber yang lain.
Data CSV menyimpan data dalam format jadual di mana setiap lajur dipisahkan dengan koma dan rekod baharu diperuntukkan kepada baris baharu. Ini menjadikannya pilihan yang sangat baik untuk mengeksport pangkalan data seperti pangkalan data SQL, data Cassandra dan banyak lagi.
Oleh itu, tidak menghairankan bahawa anda akan menghadapi senario di mana anda perlu mengimport fail CSV ke dalam pangkalan data anda.
Matlamat tutorial ini adalah untuk menunjukkan kepada anda kaedah cepat dan mudah untuk mengimport fail CSV ke dalam kelompok Elasticsearch anda menggunakan papan pemuka Kibana.”
Jom masuk.
Keperluan
Sebelum menyelam, pastikan anda mempunyai keperluan berikut:
- Kelompok Elasticsearch dengan status kesihatan hijau.
- Pelayan Kibana disambungkan ke kelompok Elasticsearch anda.
- Kebenaran yang mencukupi untuk mengurus indeks pada kelompok anda.
Contoh Fail CSV
Seperti biasa, keperluan pertama ialah fail CSV sumber anda. Adalah baik untuk memastikan bahawa data dalam fail CSV anda diformat dengan baik dan ia tidak mengandungi ralat.
Untuk tujuan ilustrasi, kami akan menggunakan set data percuma yang mengandungi filem dan Rancangan TV daripada Amazon Prime.
Buka penyemak imbas anda dan navigasi ke sumber di bawah:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Ikut prosedur untuk memuat turun set data ke mesin tempatan anda. Anda boleh mengekstrak arkib yang dimuat turun dengan arahan:
$ buka zip a~ / Muat turun / arkib.zip
Import Fail CSV
Setelah anda menyediakan fail sumber anda, kami boleh meneruskan dan membincangkan cara mengimportnya.
Mulakan dengan menuju ke papan pemuka rumah Kibana anda dan pilih pilihan 'muat naik fail'.
Cari fail CSV sasaran yang anda ingin import dalam tetingkap pelancar.
Pilih fail sumber anda dan klik muat naik.
Benarkan Elasticsearch dan Kibana menganalisis fail yang dimuat naik. Ini akan menghuraikan fail CSV dan menentukan format data, medan, jenis data, dsb.
NOTA: Bergantung pada konfigurasi kluster anda dan saiz data, proses ini mungkin mengambil sedikit masa. Pastikan nod induk bertindak balas untuk mengelakkan tamat masa.
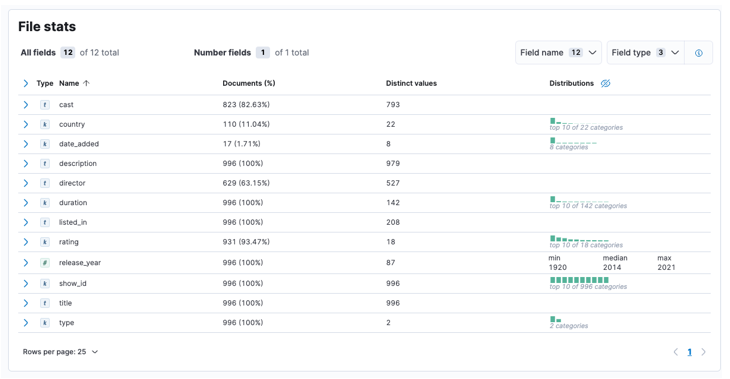
Setelah proses selesai, anda harus mendapatkan sampel kandungan fail anda dan statistik fail seperti yang dianalisis oleh Elastic.
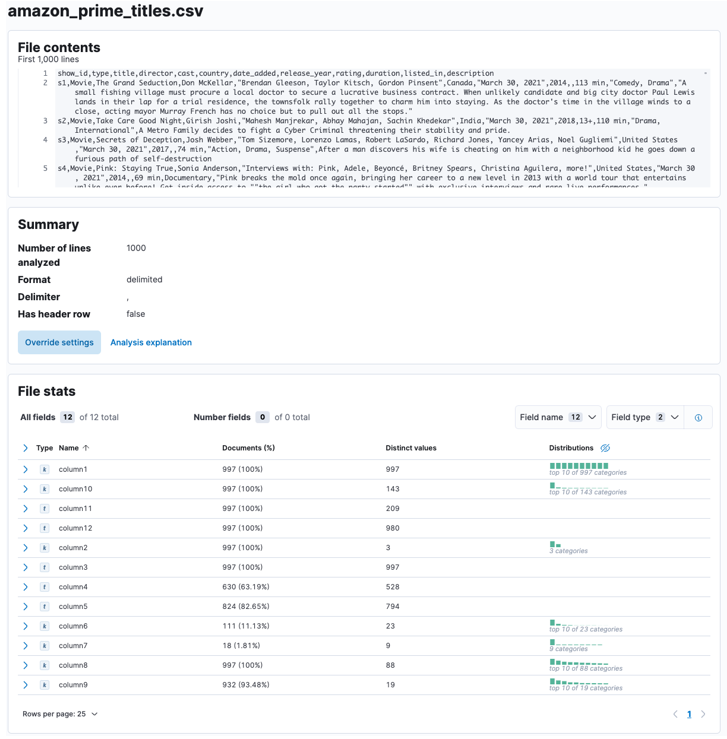
Anda boleh menyesuaikan banyak parameter, contohnya, pembatas, baris pengepala, dll. Contohnya, kami boleh menyesuaikan output di atas untuk memberitahu Elastic bahawa fail CSV kami mengandungi fail pengepala.
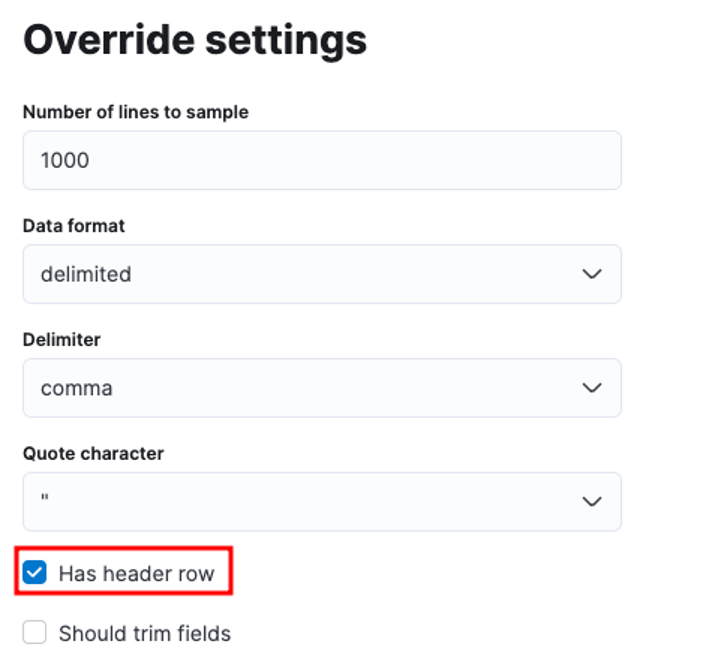
Kami kemudiannya boleh mengklik gunakan dan menganalisis semula data. Ini harus memformat data dalam format yang betul, termasuk medan.
Seterusnya, kita boleh mengklik import untuk meneruskan ke papan pemuka yang diimport.
Di sini, kita perlu mencipta indeks di mana data CSV disimpan. Anda boleh memperuntukkan sebarang nama yang disokong pada indeks anda.
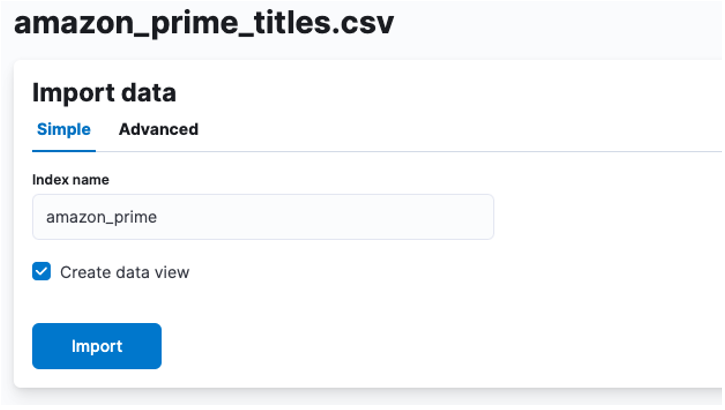
Jika anda ingin menyesuaikan sifat indeks anda, seperti bilangan serpihan, replika, pemetaan, dsb. Pilih pilihan lanjutan dan tweak tetapan anda mengikut kehendak hati anda.
Akhir sekali, klik import dan saksikan Kibana melakukan 'sihir'nya. Setelah selesai, anda boleh mengakses indeks anda sama ada melalui Elasticsearch API atau menggunakan papan pemuka Kibana.
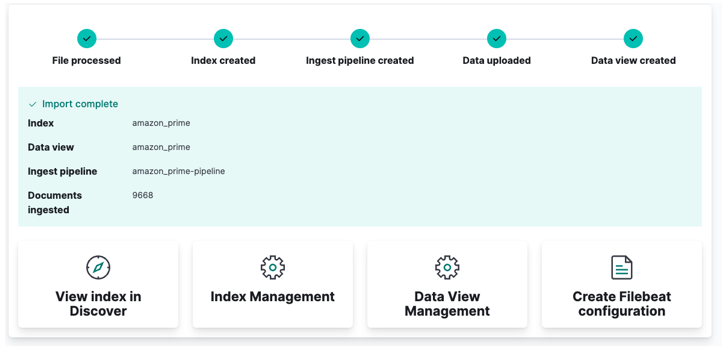
Dan anda sudah selesai!!
Kesimpulan
Dalam siaran ini, kami membincangkan proses mengambil dan mengimport set data CSV anda ke dalam kelompok Elasticsearch anda menggunakan papan pemuka Kibana.
Terima kasih kerana membaca & Selamat mengekod!!